
Lorsque l’on souhaite mettre en place une architecture microservices, la question de la base de données se pose rapidement. L’utilisation d’une seule et unique base de données partagée par l’ensemble des microservices peut représenter une vraie limite d’un point de vue architectural. En effet, cela va à l’encontre de l’architecture microservices et du principe d’indépendance et de faible couplage des microservices.
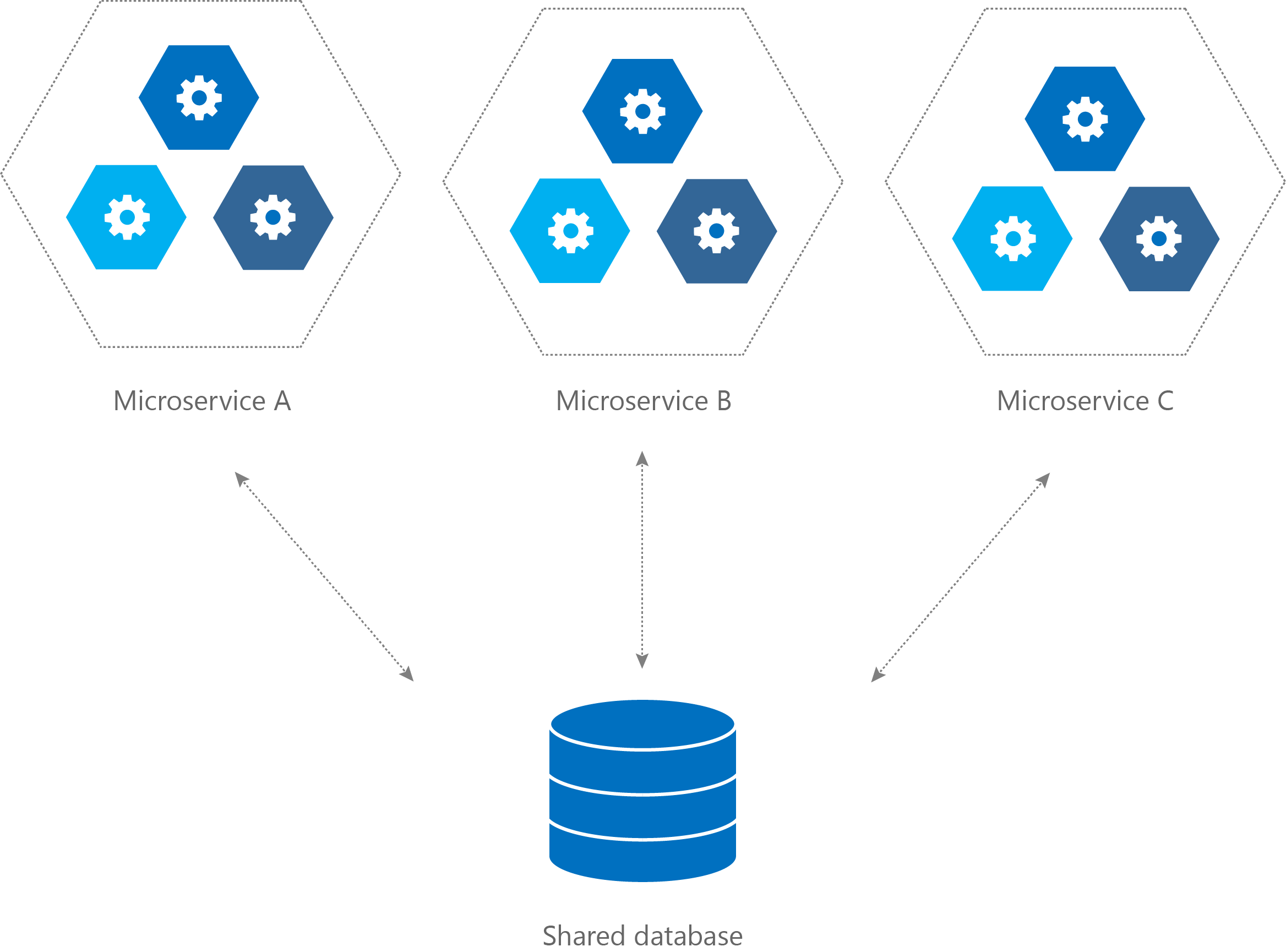
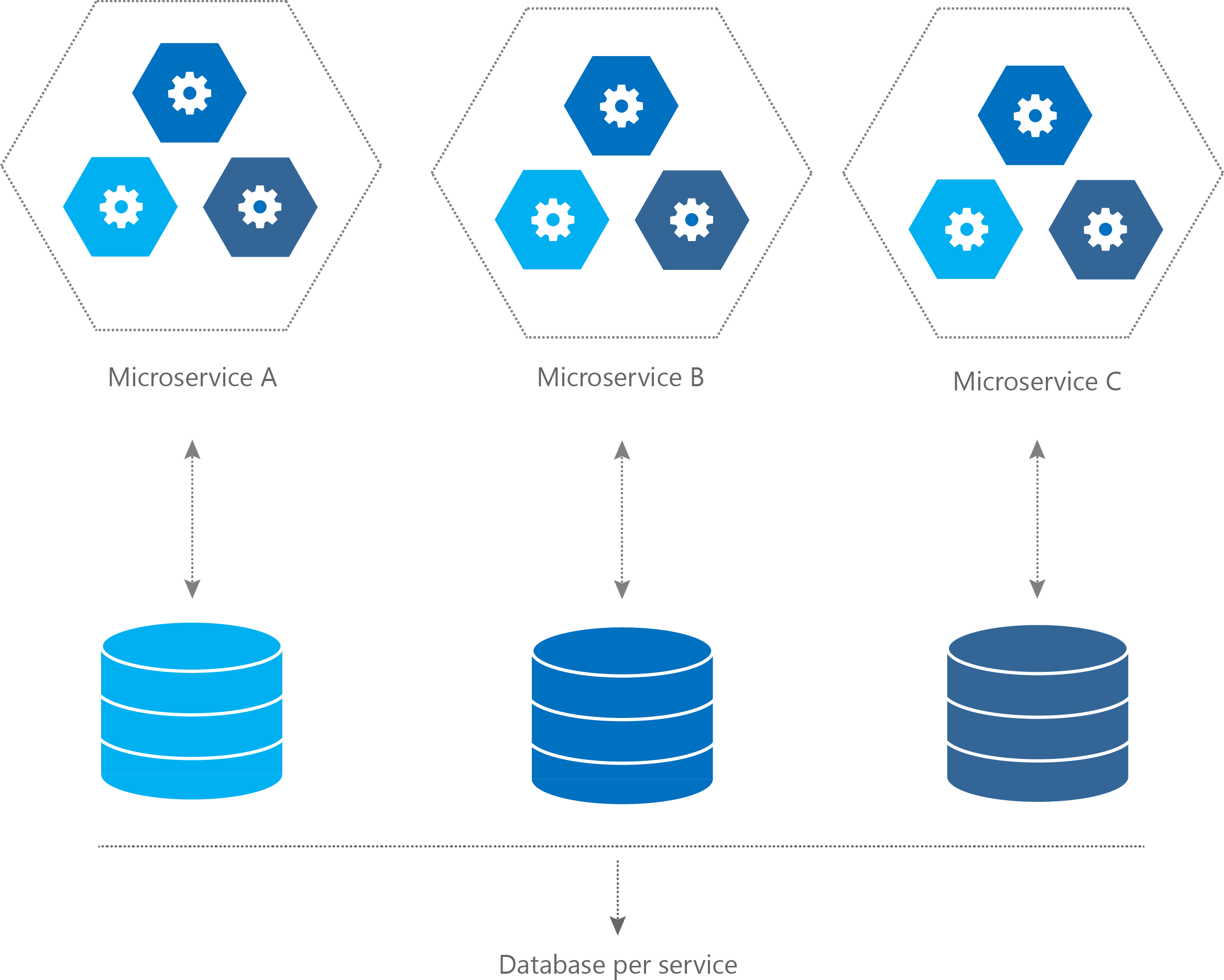
Figure 1 – Une base partagée à gauche et d’autres réservées à droite
C’est pour cette raison que le pattern d’une base de données par service peut s’avérer être une bonne option comparée à une base de données partagée. Notamment lorsque l’application commence à prendre du volume et que le nombre de services se multiplie. Cela oblige à être rigoureux sur le découpage des modèles et à limiter le couplage qui en découle pour éviter de multiplier les interactions de type « spaghetti » entre les différents microservices.

Nous avons adopté ce pattern dans un projet de R&D chez SpikeeLabs. Il consistait à passer d’une BDD monolithe pour notre solution de facture BillingLabs à plusieurs. Nous avons divisé cette BDD en plusieurs réservées par microservice pour une question de scalabilité. Avec la mise en place de ce pattern, malgré la réduction du couplage, certaines données ont parfois besoin d’être dupliquées dans plusieurs bases de données et les changements doivent être répercutés dans chaque BDD avec une latence très faible. Pour résoudre ce problème de synchronisation des données, nous avons utilisé Apache Kafka Connect et Debezium. Kafka Connect est une plateforme de messagerie distribuée qui permet de centraliser les flux de données et qui va agir comme un bus entre les systèmes sources et les systèmes cibles. Debezium fournit quant à lui une grande quantité de connecteurs permettant de s’interfacer avec plusieurs types de base de données.

Figure 2 – Synchronisation entre deux bases de données SQL Server à l’aide de Kafka et Debezium
Cette synchronisation est basée sur le principe de « Change Data Capture ». À chaque modification de données dans une table source, les évènements associés vont être détectés et répartis dans des files de messages auxquelles les différents lecteurs (ou sink) sont abonnés. Par exemple, dans la figure suivante, la table « comptes » est uniquement disponible en écriture par l’API comptes :
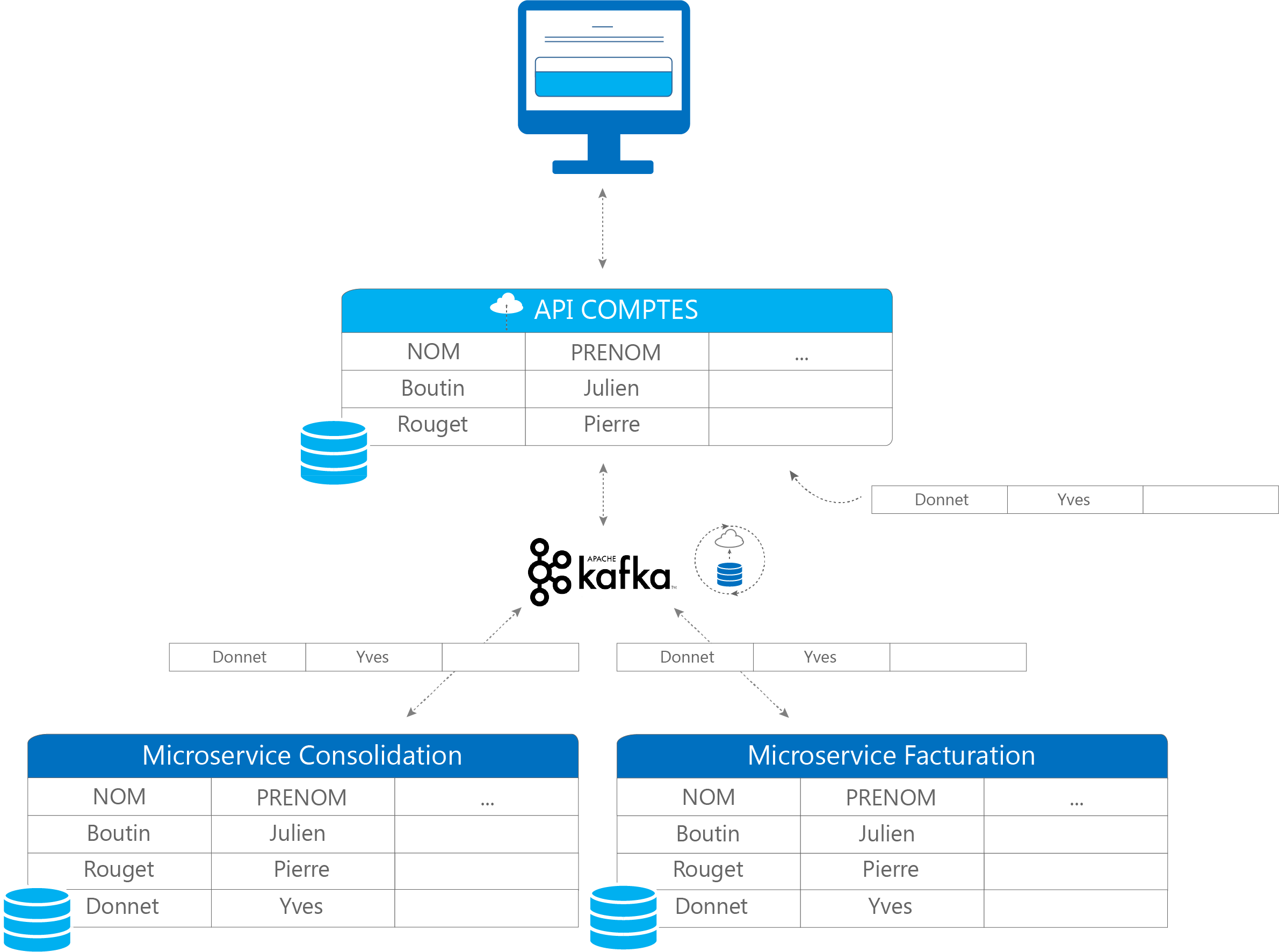
Figure 3 – Mécanisme de recopie des données à l’aide de Kafka
Les tables des microservices de consolidation et facturation sont abonnées au « topic » comptes et sont donc lecteurs de cette table. A chaque fois qu’une donnée est modifiée, créée ou bien supprimée dans la table source, les changements vont être détectés et répercutés dans la base de données des lecteurs (ou sink). Pour conclure, ce pattern apporte de vrais avantages par rapport à l’utilisation d’une base de données partagée, particulièrement sur les aspects de scalabilité et de séparation des services. Cependant, sa mise en place peut être assez coûteuse notamment pour la refonte d’applications existantes et nécessite une architecture bien définie dès le départ.
Vers le 2° design patterns